





























































[wpforms id="548" title="false" description="false"]



Successful activity since 2004!
We have 69 objects of intellectual property
Cooperation with leading universities, specialized publications and standardization committees
Solutions for various industries
Long-term experience of profitable cooperation
We are inventors
We have 69 objects of intellectual property!
We are scientists
We are developers
In 2015 Nordavind Group entered the market of telemedicine with a unique mobile complex for self-monitoring of the cardiovascular system.
During 3 years 3 devices have been developed: ECG Dongle, ECG Dongle Full and holter monitor “RHYTHM”, mobile application and cloud service “CardioCloud”. 2 devices have been started in batch production.
Over 12 000 devices were released, the mobile application was downloaded more than 1500 times, cardiologists in the cloud service decoded more than 1300 electrocardiograms.
ECG Dongle is the winner of the contest "Made in Moscow".
Electrocardiographs ECG Dongle and ECG Dongle Full are used in 82 countries.
Over 12 000 devices were released, the mobile application was downloaded more than 1500 times, cardiologists in the cloud service decoded more than 1300 electrocardiograms.
ECG Dongle is the winner of the contest "Made in Moscow".
Electrocardiographs ECG Dongle and ECG Dongle Full are used in 82 countries.

Since 2017 we have been developing in the field of Blockchain
We created:
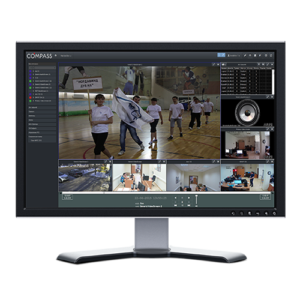
We are pioneers in the market of software solutions for the organization of Linux-based video surveillance systems.
Our first product – CCT “TeleWizard” was introduced in 2004.
At present the list of developed solutions in the field of intelligent video analytics has 10 basic products and many adapted versions for specific tasks.
At present the list of developed solutions in the field of intelligent video analytics has 10 basic products and many adapted versions for specific tasks.
Our team
-

Ilya Svirin
CEO of JSC “Nordavind”
Founder and leader of the Nordavind Group
-

Nadezhda Nabilskaya
CEO of LLC “Nordavind-Dubna”
-

Ekaterina Epishina
CEO of LLC “Scientific enterprise “Tsezis”
-

Elena Yuferova
CEO`s adviser on strategic management and staff relations
-

Ivan Svirin
CEO of LLC “Interindustry Automation Bureau”